
hledger and double-entry accounting#
hledger describes itself as follows:
hledger is lightweight, cross platform, multi-currency, double-entry accounting software. It lets you track money, investments, cryptocurrencies, invoices, time, inventory and more, in a safe, future-proof plain text data format with full version control and privacy.
What I like the most about hledger is, that it works on plain text files, allowing me to utilize many tools/workflows I am used to:
- I can grep through my accounting data.
- I can easily back up my accounting data.
- I can put my accounting data under version control with Git.
- I can sync my accounting data with Syncthing.
One thing, that I was not used to, was double-entry accounting. But thanks to hledger, I have now a (very) basic understanding of it. The most important, and probably most confusing, thing with double-entry accounting is that you always have two transactions so that the sum is always zero. Let me explain this for you with a simple example. You buy bread for 2 € and the entry in your journal file would look like as follows:
commodity €2023-03-26 Bread
expenses:lebensmittel 2
assets:cash -2
You can see that there is a positive amount on my expenses:lebensmittel (groceries) account and a negative amount booked on my assets:cash account. So, my cash account is charged to pay 2 € to the (virtual) expenses:lebensmittel account.
When I receive money, for instance my salary, it is the other way around. The (virtual) account of my company is charged with the amount of my salary that is booked on my bank asset.
2023-03-26 Salary
assets:bank 1000
expenses:mijope -1000
Adding entries#
My workflow for adding entries consists of an Alfred workflow1 that runs my terminal of choice, kitty, and executes hledger add.

LEDGER_FILE to get the path to the journal file. Alternatively, you can invoke hledger with -f path/to/your/ledgerfile.hledger does assist you with auto-completion of accounts and with suggestions based on older entries.
After each year, I point my main.ledger file via symlink to a new <year>.ledger file and start with a new initial balance.
.
├── 2016.db
├── 2016.ledger
├── 2017.db
├── 2017.ledger
├── 2018.db
├── 2018.ledger
├── 2019.db
├── 2019.ledger
├── 2020.db
├── 2020.ledger
├── 2021.db
├── 2021.ledger
├── 2022.db
├── 2022.ledger
├── 2023.ledger -> main.ledger
├── all.db
├── all.ledger
└── main.ledger
all.ledger “consists” of all my ledger files with the include directive: include 20*.ledger. In the next chapter, I will talk about what’s up with those db files!
Visualizing and Analyzing2#
My goal is, to give me the opportunity, to answer the following questions:
- What is the trend of my expenses?
- On what stuff do I spend money?
- Are there any spikes / anomalies?
Naturally, we can answer those questions best with charts and dashboards! What do I need to generate dashboards in an interactive and explorative way? Luckily, there are tools that support business intelligence teams (in a way more sophisticated way) to find answers to such questions3.
My choice fell on the open-source version of metabase which describes itself as follows:
Fast analytics with the friendly UX and integrated tooling to let your company explore data on their own.
You can easily spin up a (non production ready) instance via a single docker container and access its UI at http://localhost:3000:
docker run --rm -d -p 3000:3000 -v $(PWD):/app/data --name metabase metabase
-v $(PWD):/app/data mounts the current folder of your terminal on the Metabase container making the contents available for the application. Metabase can connect to various sources, but we will keep things simple and stick with SQLite. Luckily, hledger provides a command to export your transactions to SQL.
The following command outputs your journal to SQL and uses the output to create a SQLite database4:
hledger print -O sql | sed 's/id serial/id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL/g' | sqlite3 ledger.db
This command creates a database that Metabase can read an query. The fun begins!5
Impressions#
I am still at the beginning of building my queries / dashboards, but so far, it looks promising! Keep in mind that those charts are not static, but can be interactively adjusted. Amounts are blurred out. 😉
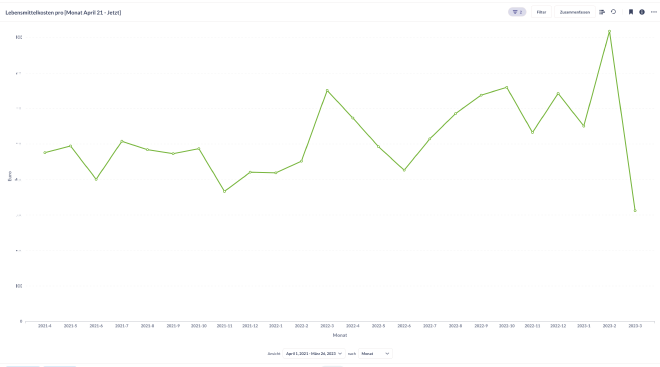


Running Metabase not locally#
I run an Unraid NAS / home lab system with a Docker host included. My data, including my ledger files, is synced to a share on this Server and Metabase is available as community, therefore, with a few clicks installed. The only adjustment I needed to do was to tell the container to mount my ledger folder.

Adding a SQLite database is straightforward. Note that the path in the application is the same as the “Container Path” container configuration.

Now, I can add and work with my databases in Metabase running on my home lab and access the dashboards from all my devices. 🚀
One could automate the generation of the SQLite files as well, but for now, I will do this manually whenever I want to analyze my data, usually at the end of a month/year.
Thanks for reading! 🤗
This is my Alfred workflow script which I have mapped to a shortcut.
↩︎on alfred_script(q) tell application "kitty" to activate do shell script "/Applications/Kitty.app/Contents/MacOS/kitty @ --to unix:/tmp/mykitty new-window --new-tab --title='hledger add'" tell application "System Events" to keystroke "hledger add" tell application "System Events" key code 36 -- enter key end tell end alfred_scriptI was inspired by the comments to my qestion on reddit on “How do you visualize / drill down your financial data with hledger” ↩︎
hledger has a quite powerful reporting included. There are various commands to query and filter your transaction and a cheat sheet like this comes in handy. There are also options to output your entries to various formats, including csv and plot your data with e.g. gnuplot. These might be sufficient for you! ↩︎
Refer to this GitHub issue for an explanation of the
sedpart. ↩︎See the Metabase docs for more details on how to work with Metabase! ↩︎